AI for Coding
Day 1: Core AI concepts
2026-04-20
Integrated Development Environment (IDE)
An IDE is the workspace for coding and executing data analysis:
- a code editor
- a console / terminal
- project navigation
- testing/debugging
- Git and extensions
- AI assistance and more…
There are many IDEs, both with user interfaces (UIs) and as command-line interfaces (CLIs).
Most are made for programming. Positron, RStudio, and JupyterLab — for data science.
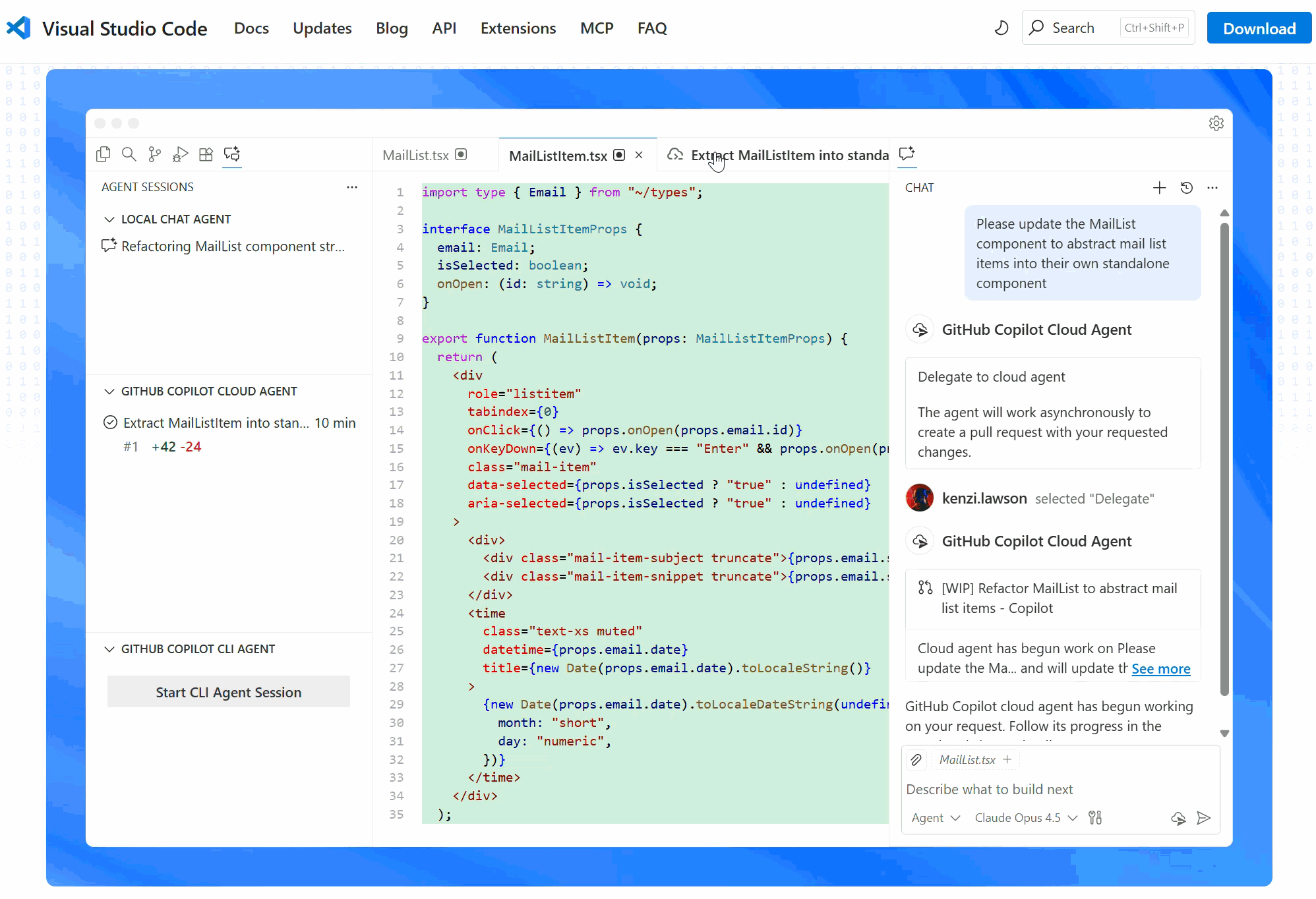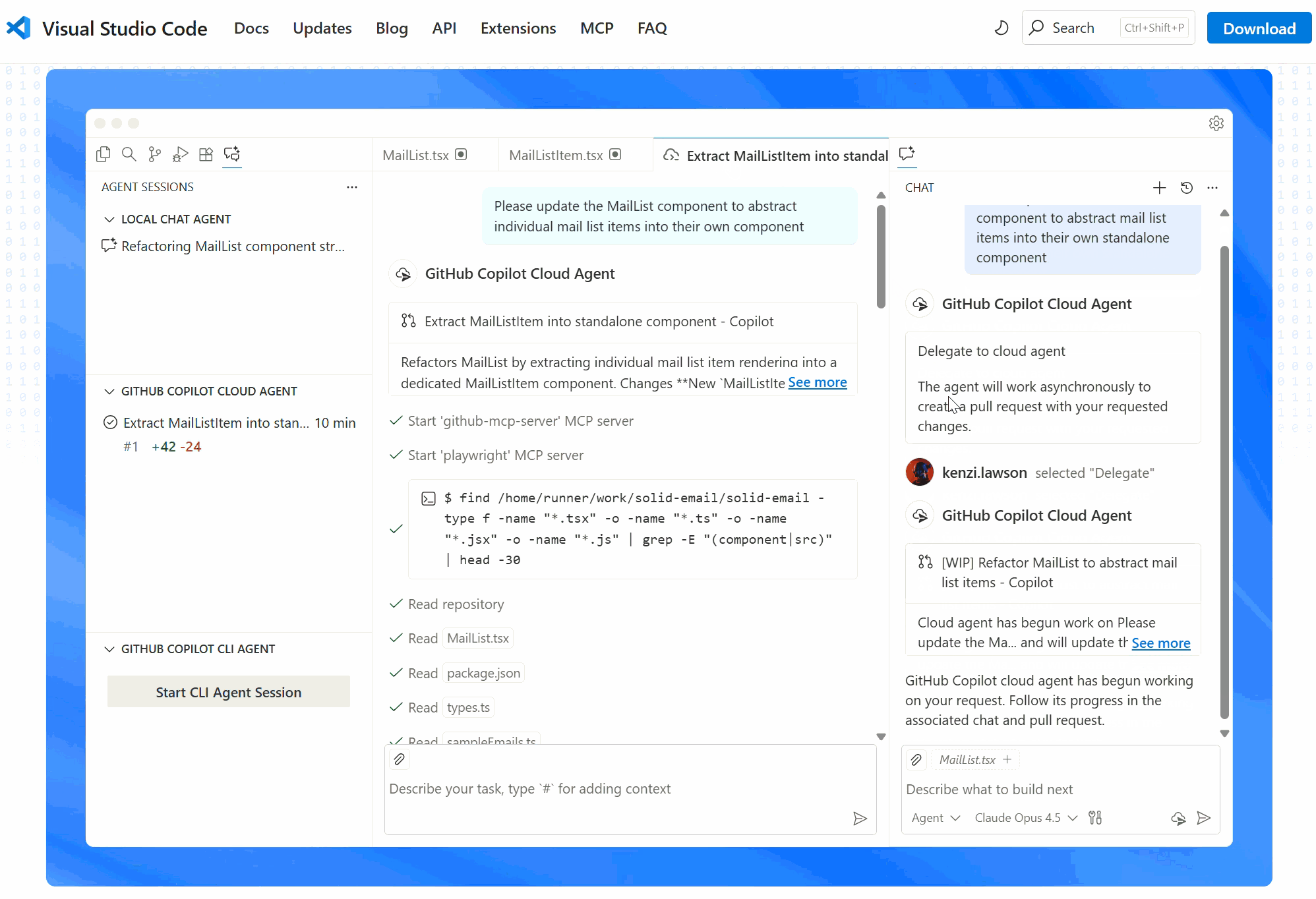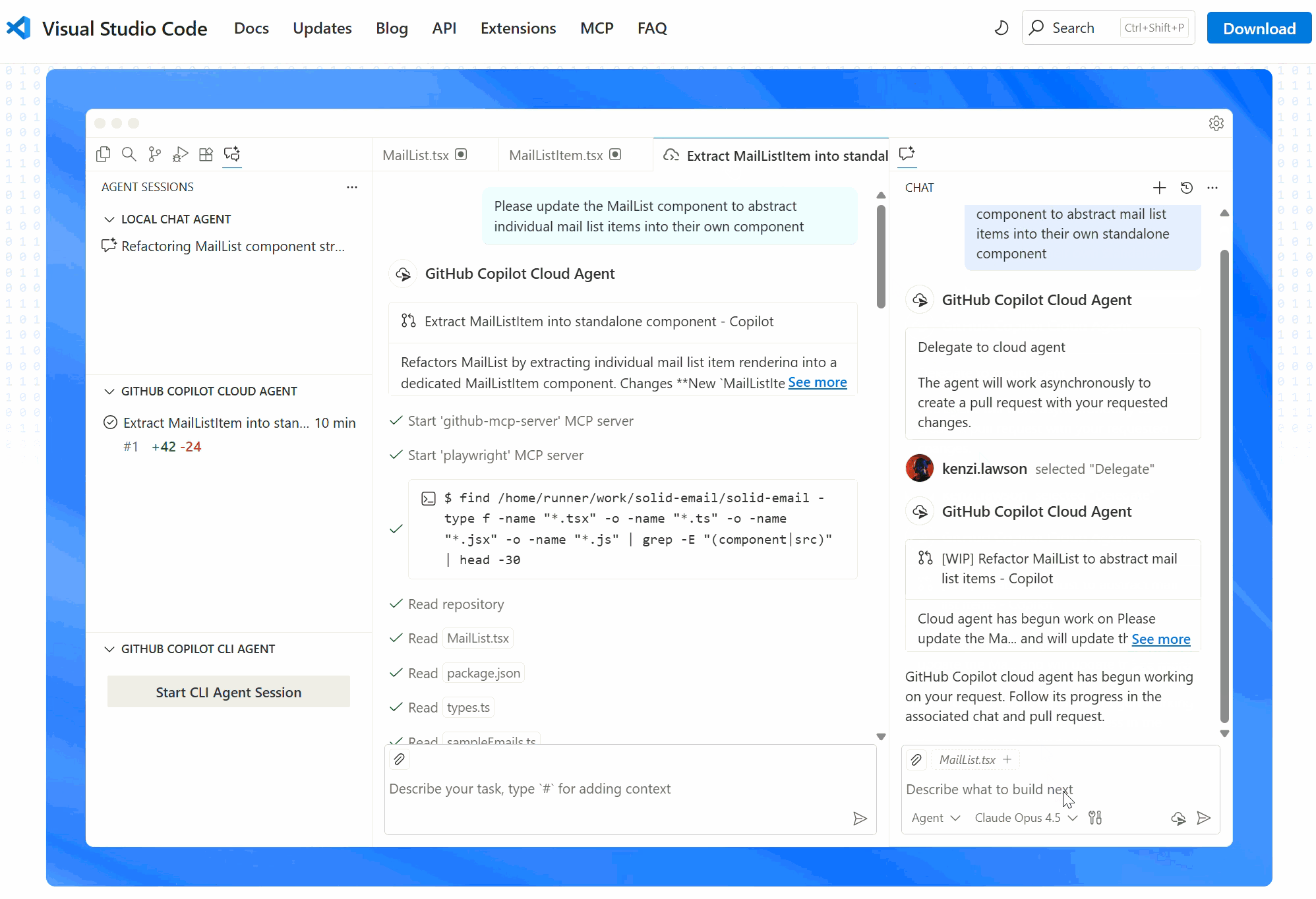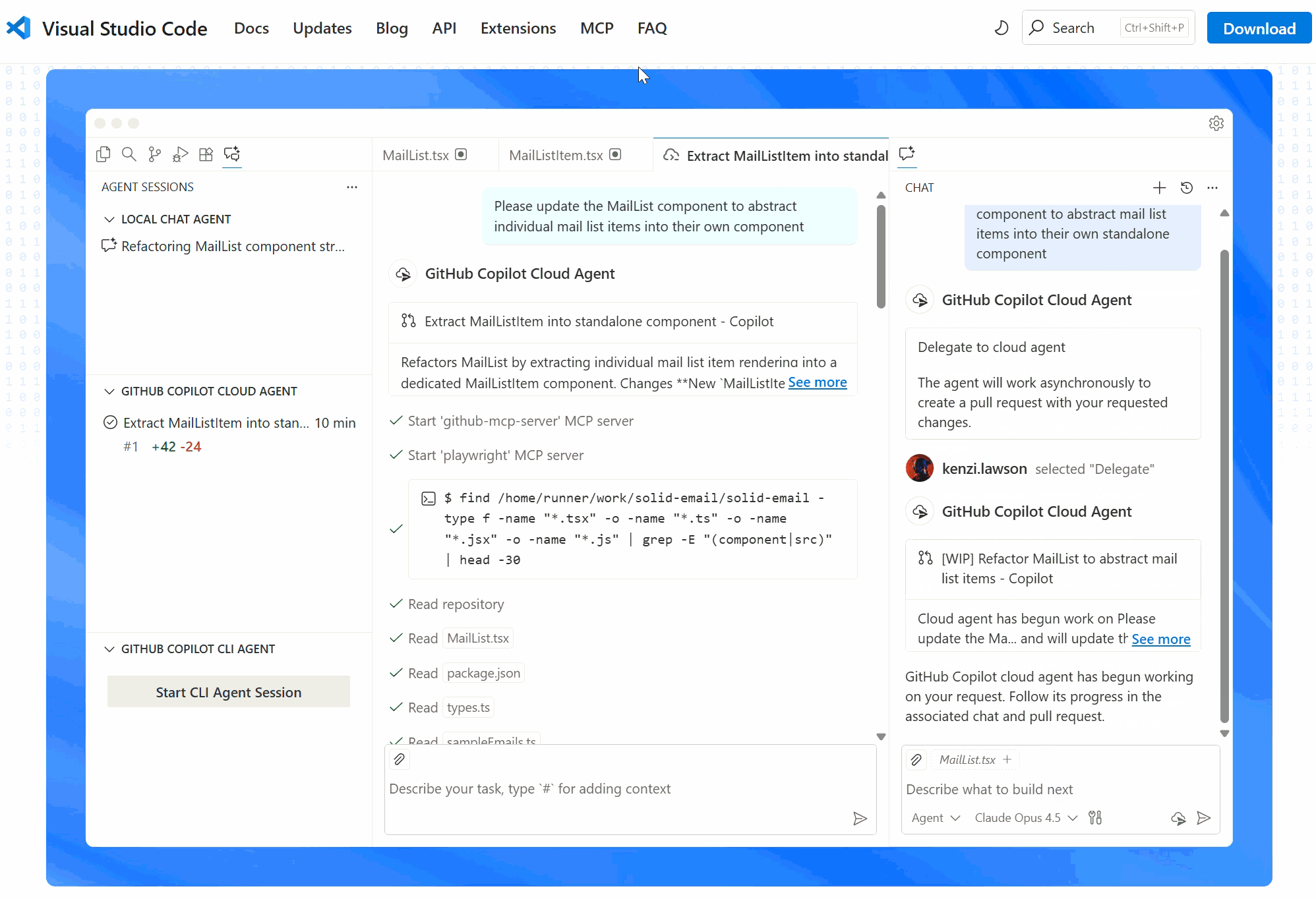
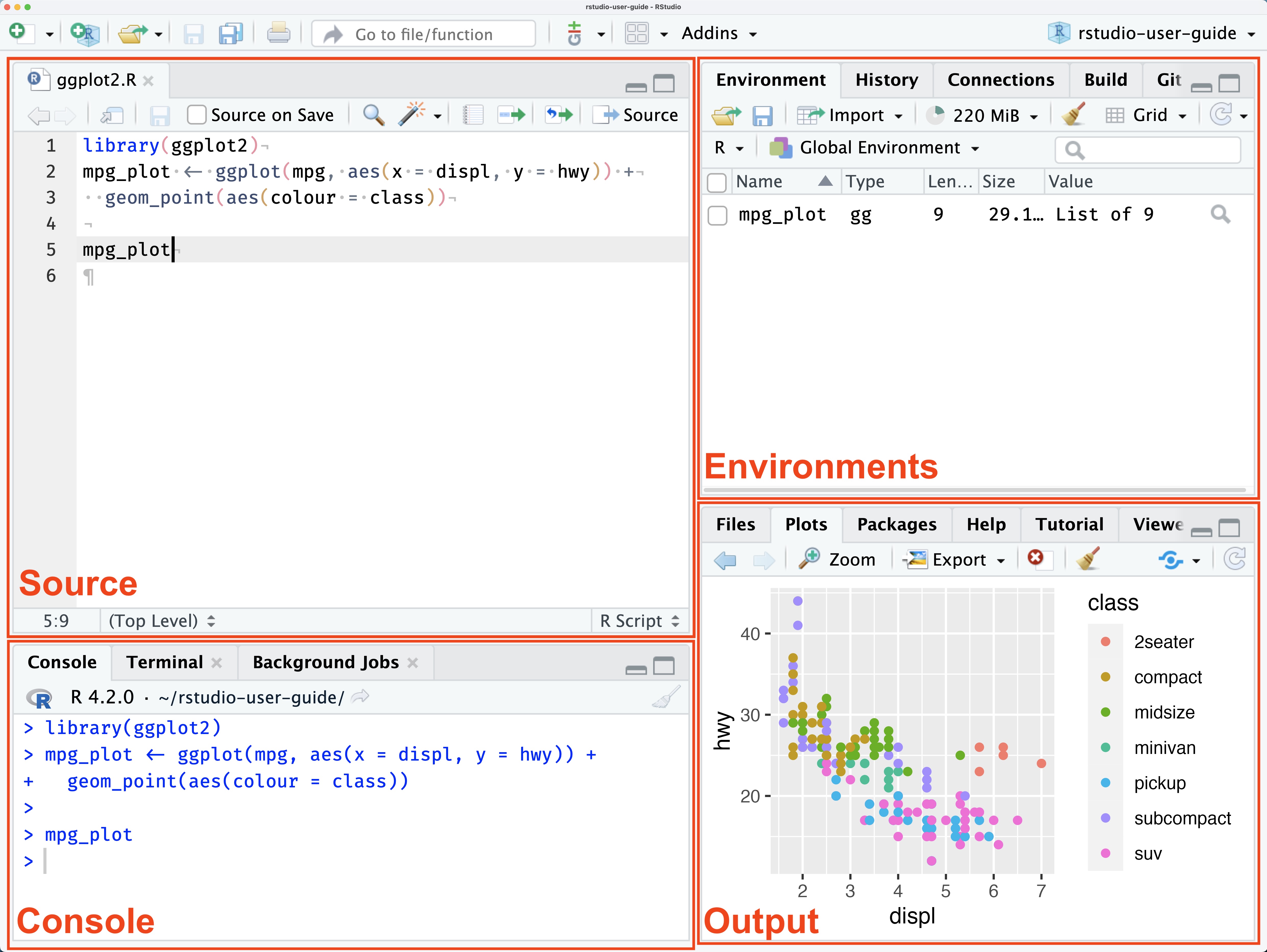
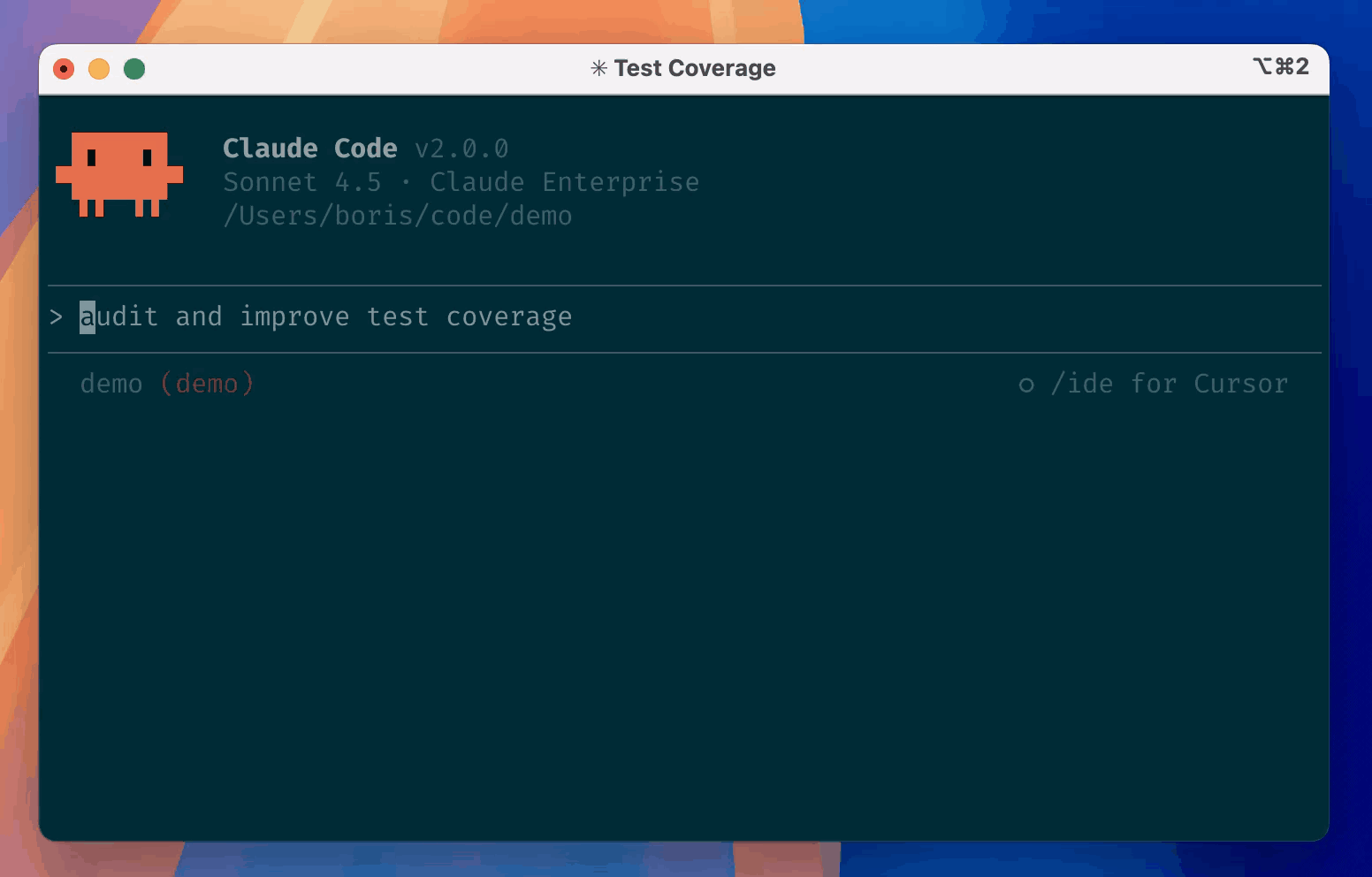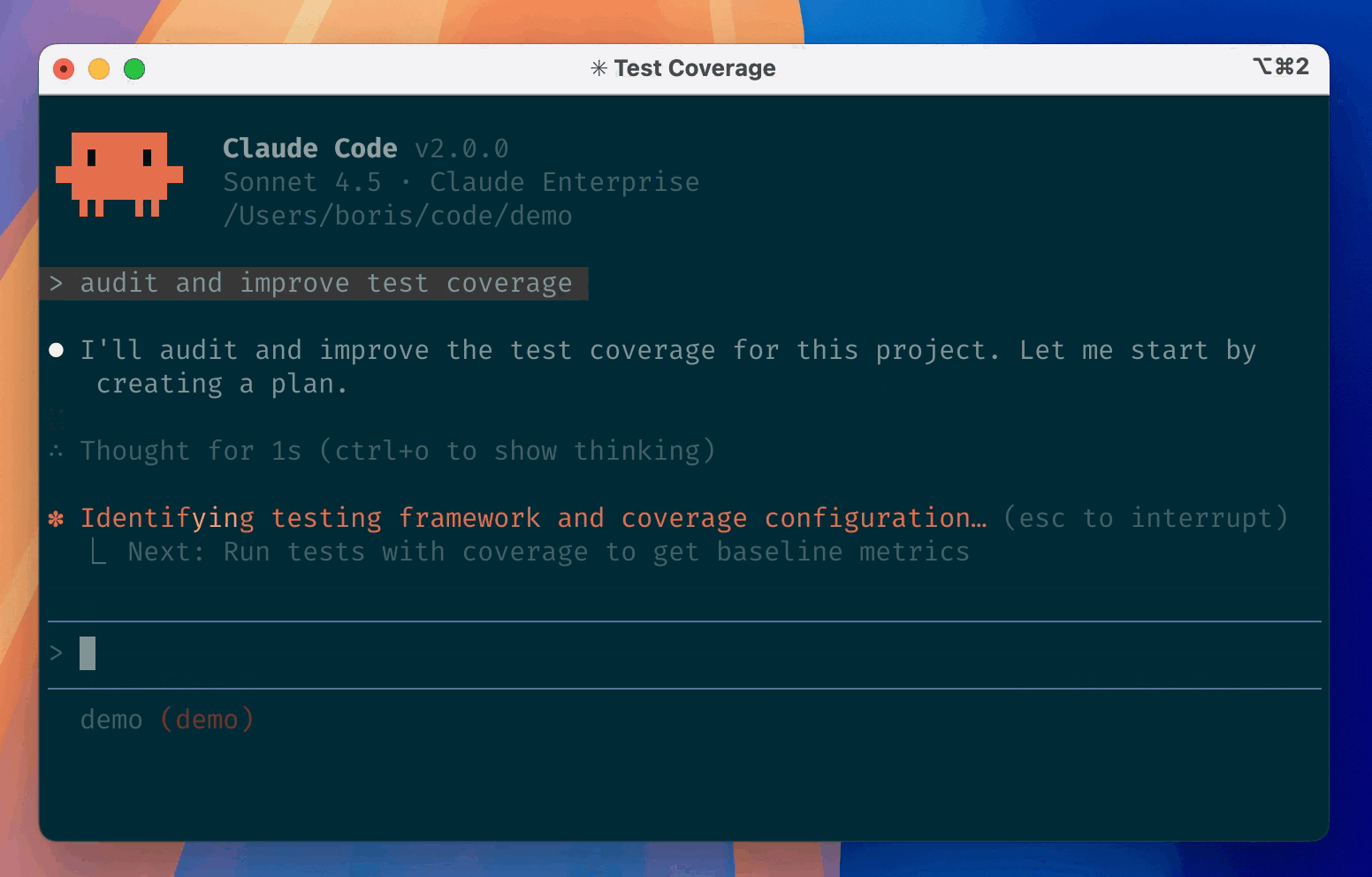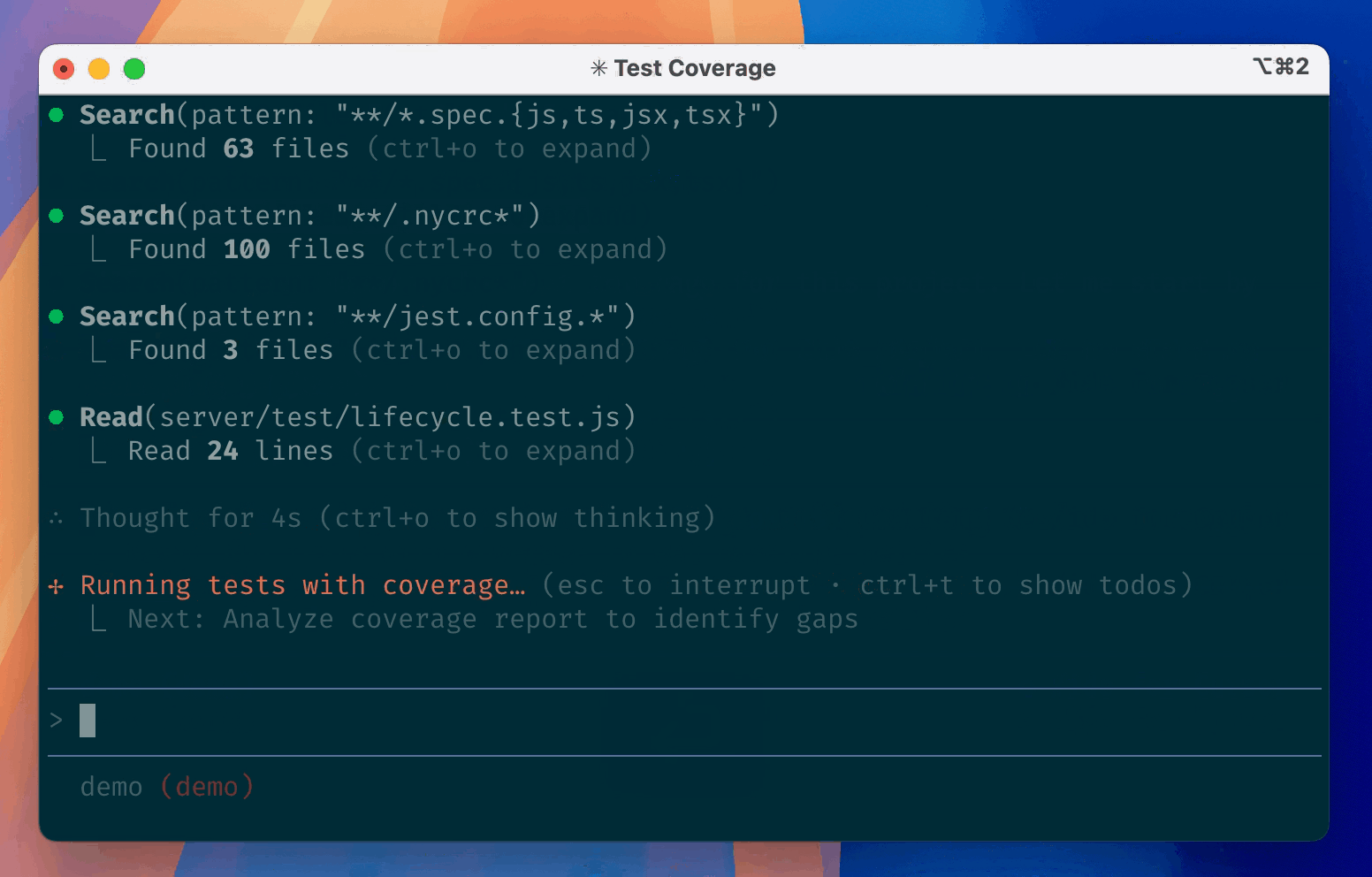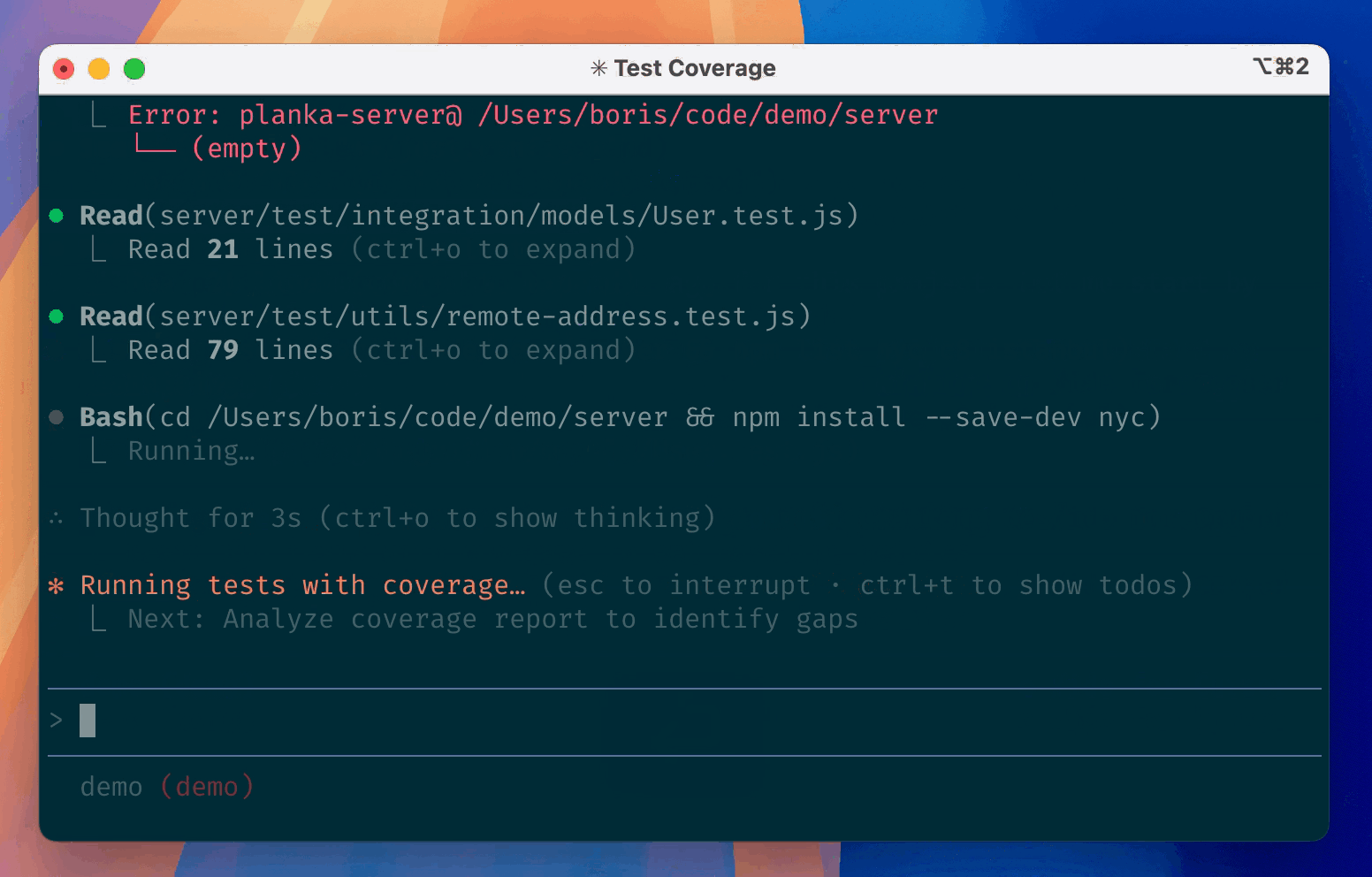
User-IDE-Assistant: workflow intuition
💻 Code, data, and analysis stay inside the IDE on the user’s computer.
Positron Assistant works in the IDE as a middleman that connects the user, IDE, and cloud-based AI services.
GitHub Copilot is a cloud-based AI orchestrator: coordinates the assistant and LLMs, submits prompts to the LLMs, and pre-processes responses before sending them back to the assistant.
🔢 The LLM:
- ingests the prompt as text,
- converts it into tokens,
- embeds tokens as numeric vectors,
- performs inference to generate a tokenized response, decodes tokens, and
- responds back to the assistant.
✅ The user controls and decides whether to accept, edit, or reject the suggested code.

Context
- 🧠 Context is key for accurate AI responses.
- Every message, file, and code snippet adds to the context.
- 🔧 Context is assembled by the IDE cumulatively.
- 📏 Size is measured in tokens.
- Context has layers: system prompt (hidden instructions that steer the LLM’s behavior in Copilot and Positron) vs. user prompt (your visible messages and attached files).
Be mindful of context size and content.
⚠️ LLMs have a maximum context window (4k–2M tokens) — exceeding it leads to information loss.

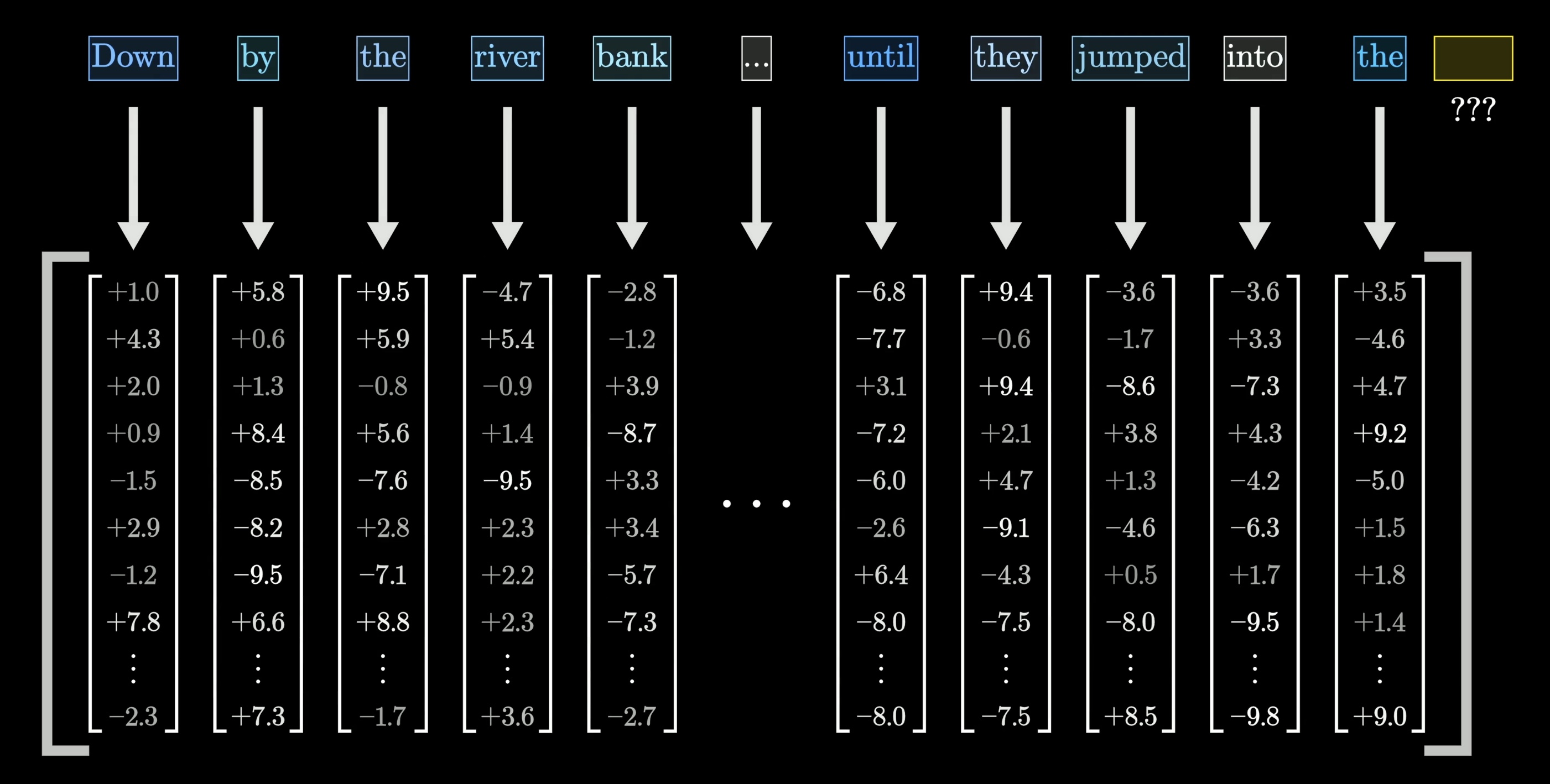
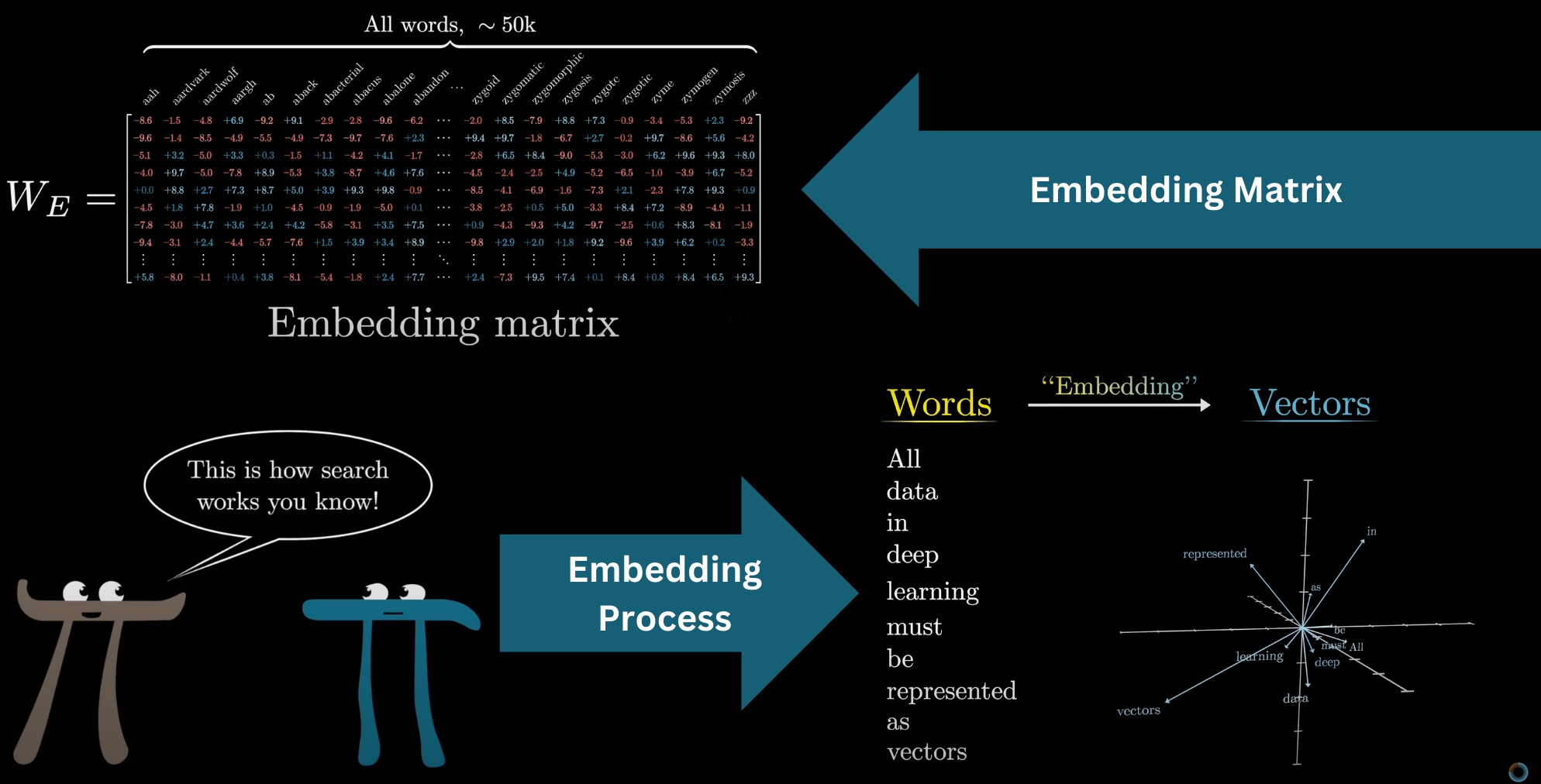
Tokens and embeddings
- 🔢 Tokens are text units (words, subwords) forming the LLM vocabulary (GPT-3: 50k tokens; Claude: speculated ~200k).
- 🧠 Each token is embedded as a numeric vector (GPT-3: 12,288 dimensions) — a sentence becomes a matrix of vectors.
LLM Training
- 🧠 LLMs are trained on massive text datasets (GPT-3: ~300B tokens / 570GB; modern models: >15T tokens).
- The model learns to predict the next token given previous tokens, updating its weights via backpropagation.
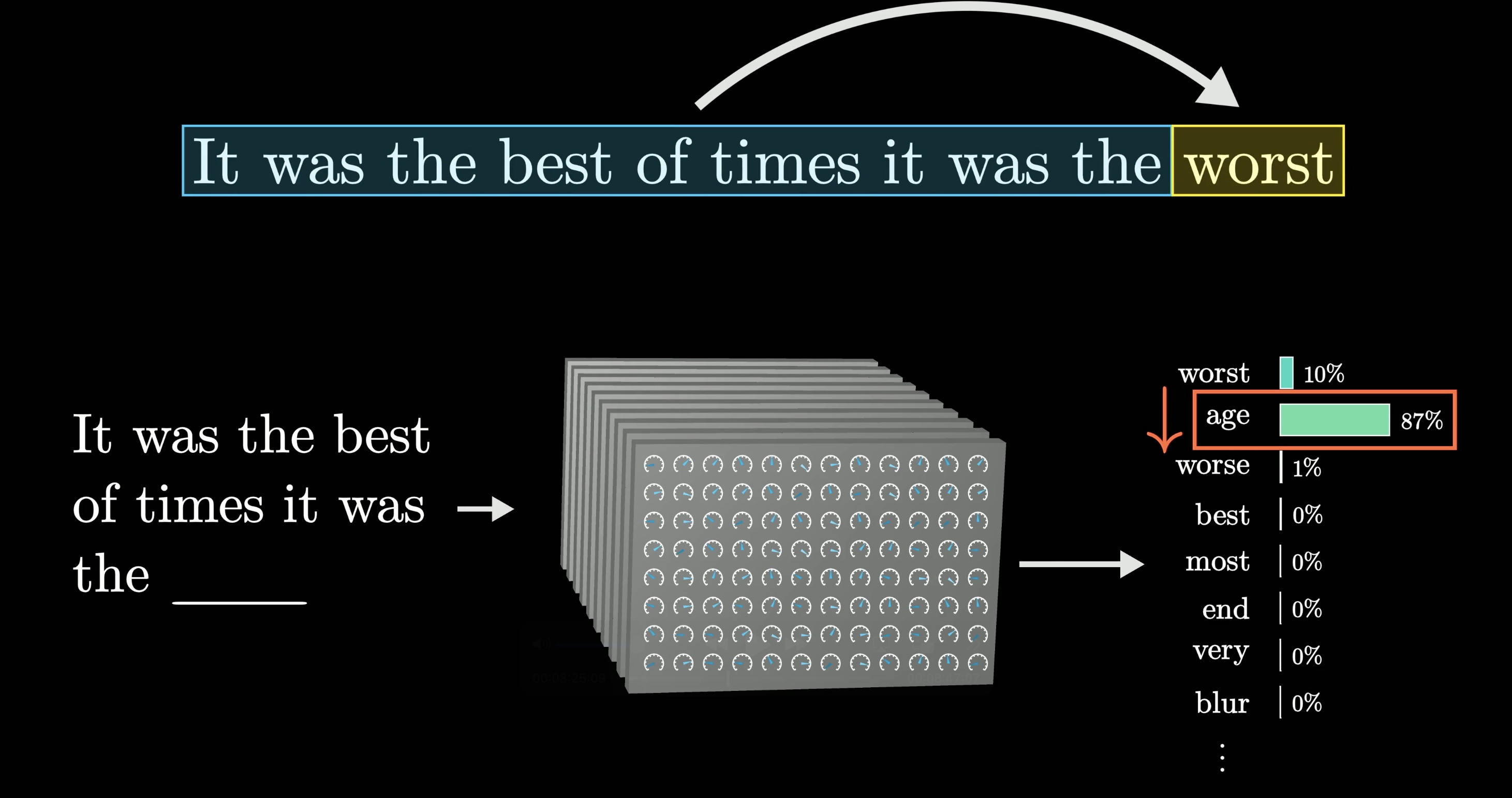

LLMs are probabilistic
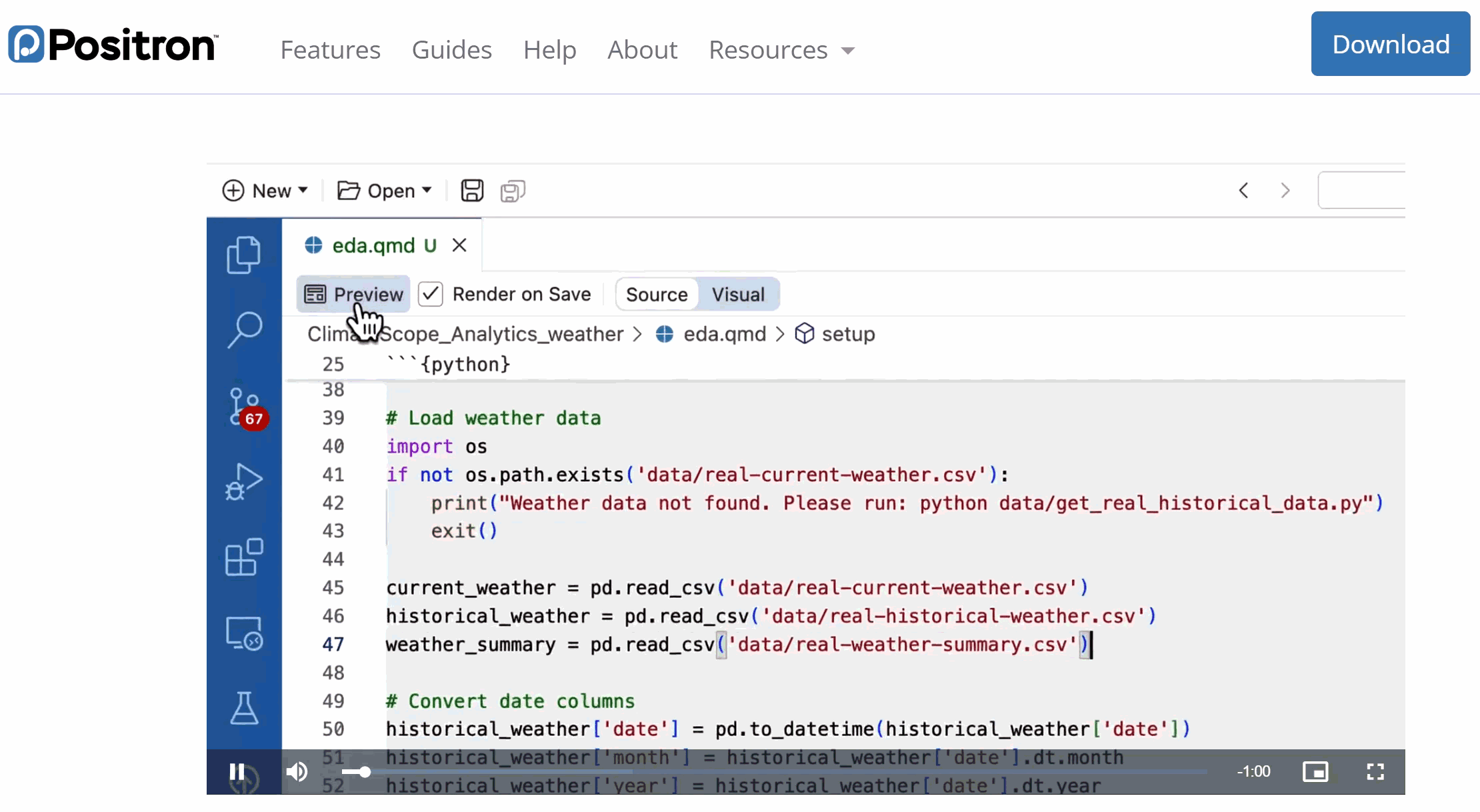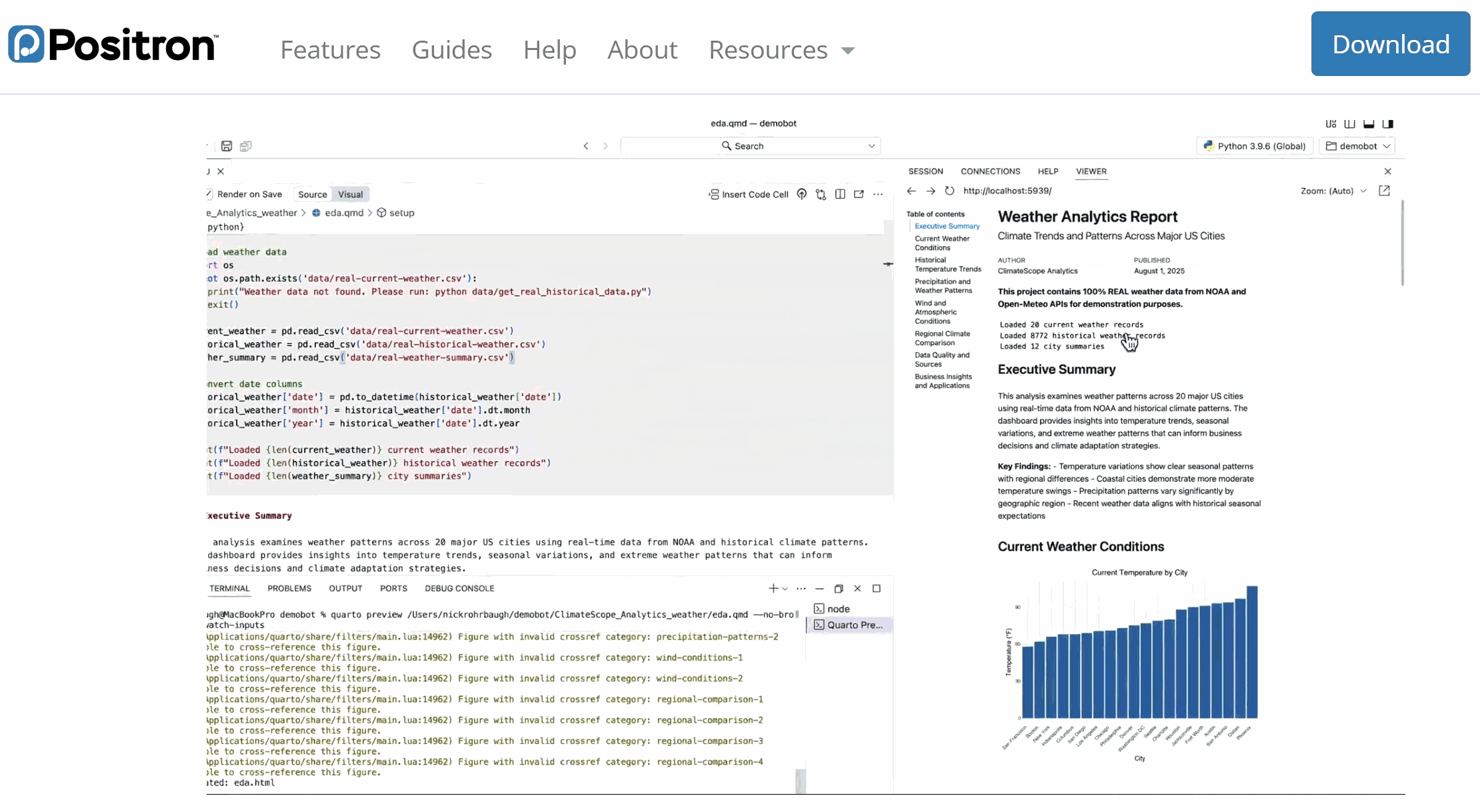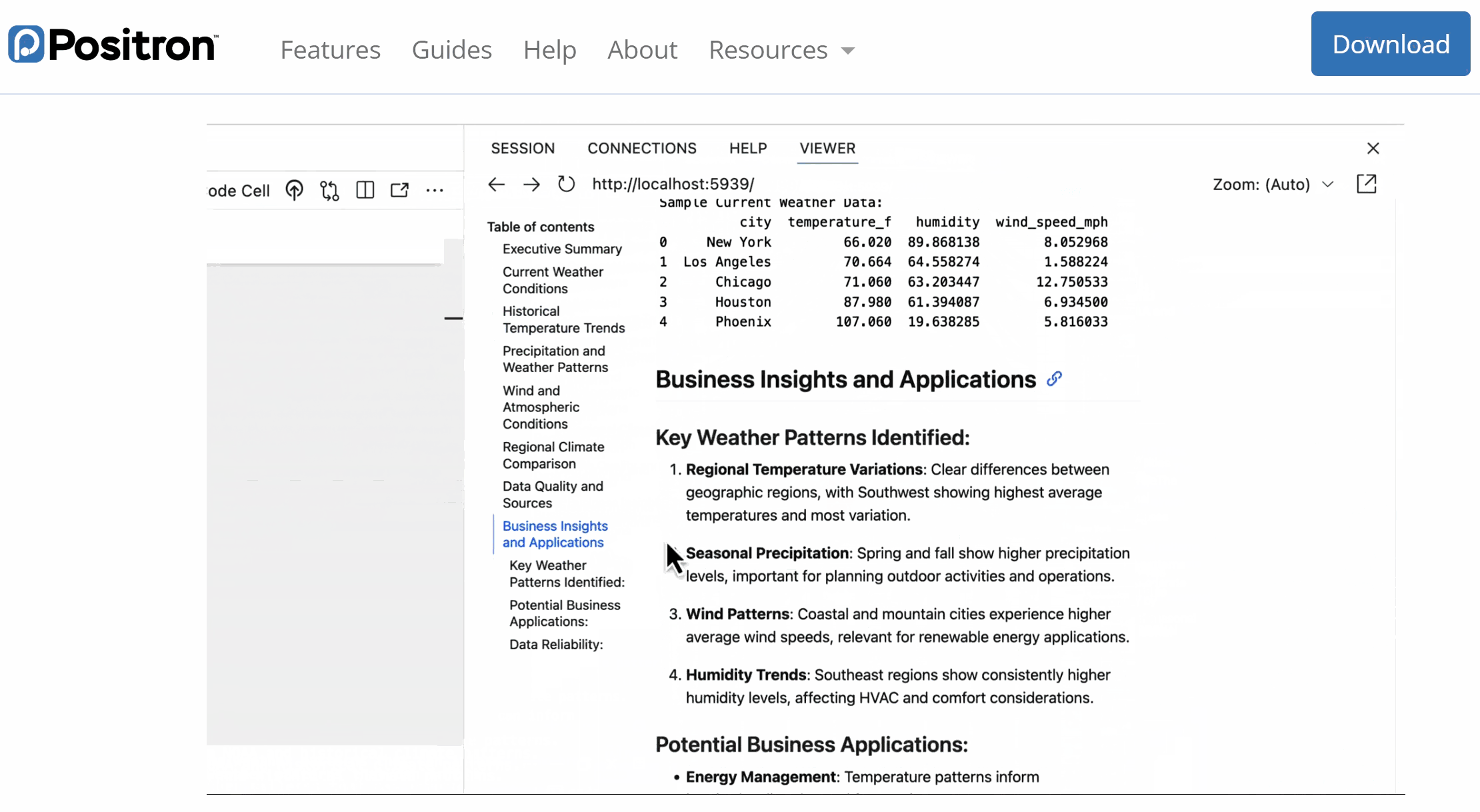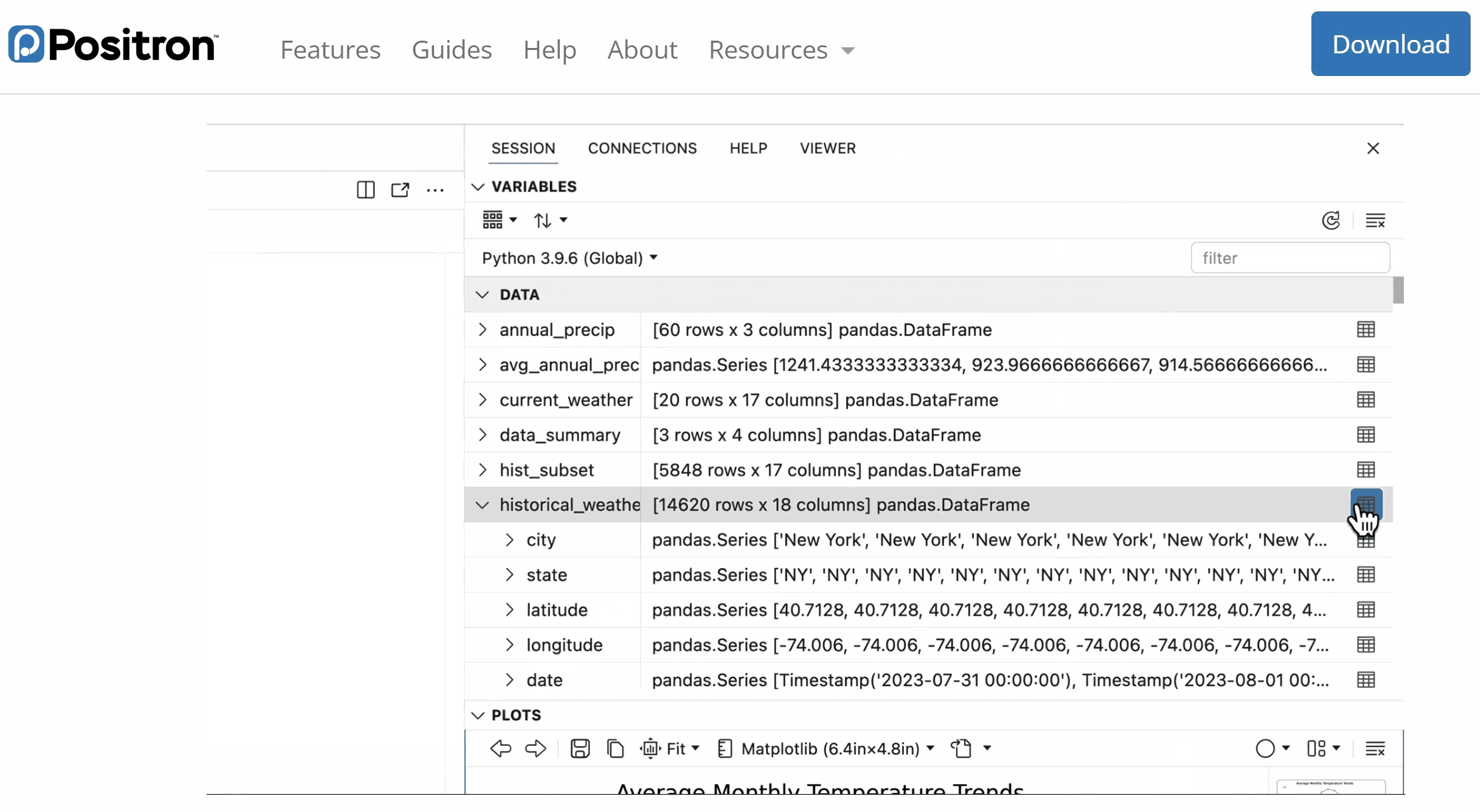
- LLMs respond with a distribution of likely next words and then sample one using a decoding strategy (e.g., Temperature or Top-k sampling).

Next-token prediction example
LLMs are context-dependent
- Responses depend on the context of the prompt.
- Context size and quality affect accuracy.
- Claude Sonnet/Opus: 64k–2M token context window (GPT-3 had 8k).

Context-dependent LLM prediction
LLM inference
- The process of generating responses based on the input prompt, which contains all the context.

LLM inference diagram
